
W
Workflow Pages That Capture Intent
Explains how workflow-oriented pages mirror how users ask AI for solutions.
Practical frameworks to help businesses navigate Answer Engine Optimization and sustainable organic expansion.
111 results
Explains how workflow-oriented pages mirror how users ask AI for solutions.
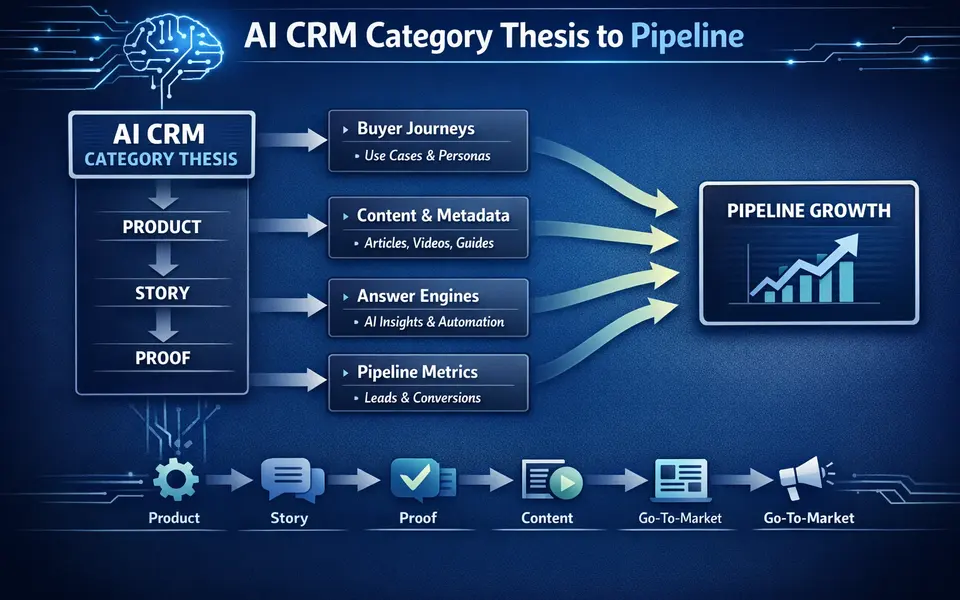
Provides a model for becoming synonymous with a category before search volume catches up.
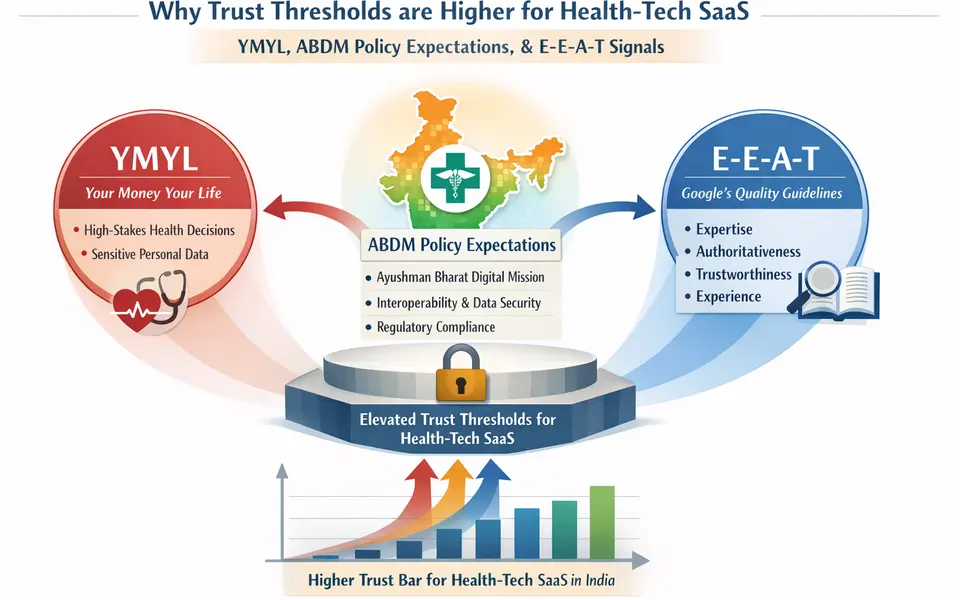
Shows how high-trust software categories need stronger authority and evidence systems.

Explains how larger software sales cycles require more proof, stakeholder content, and retrieval depth.
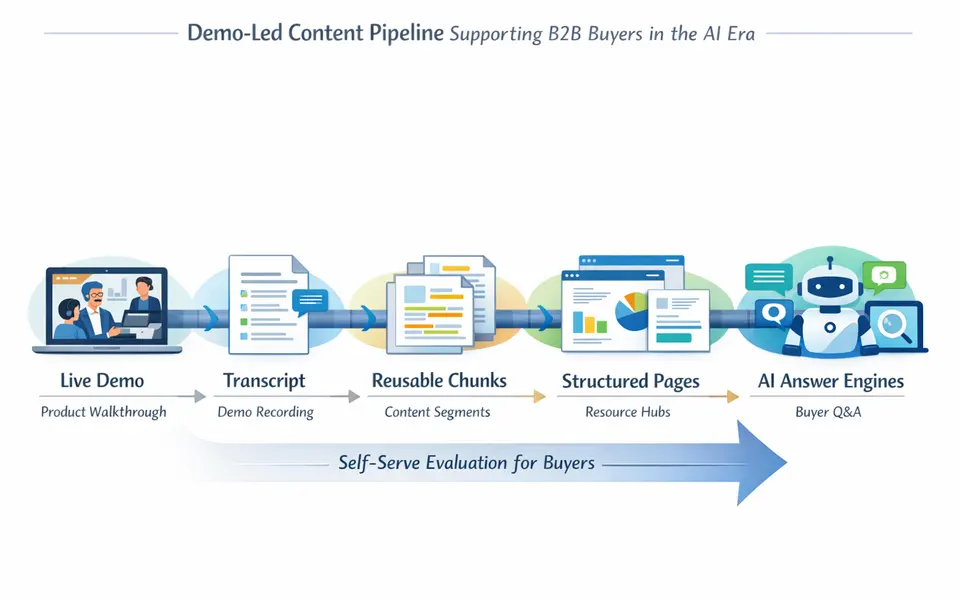
Shows how to turn demos and product walkthroughs into answer-engine-ready assets.
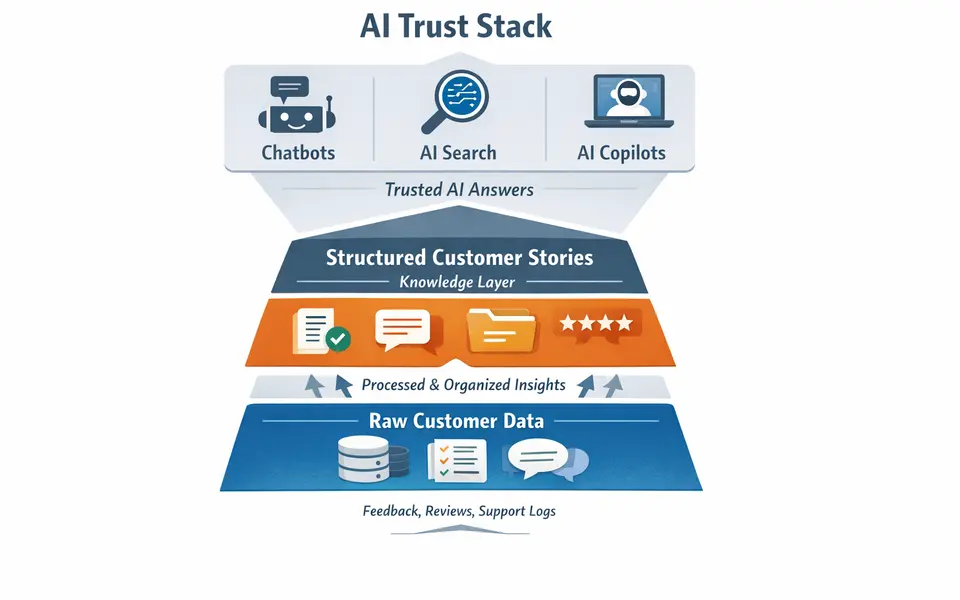
Explains how to structure outcomes, context, and evidence so customer stories inform AI answers.
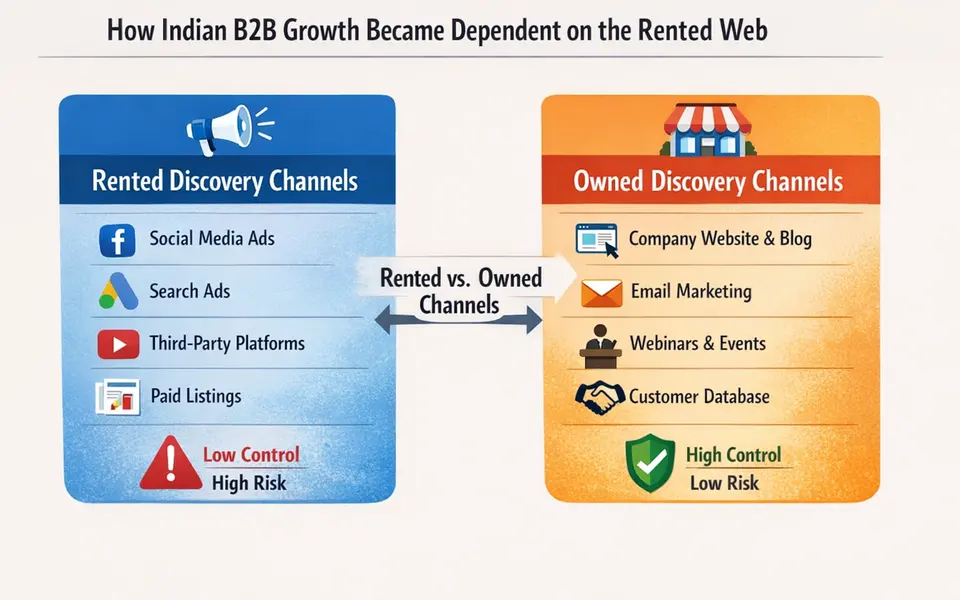
Explains why dependency on ads and third-party platforms creates fragile growth systems.
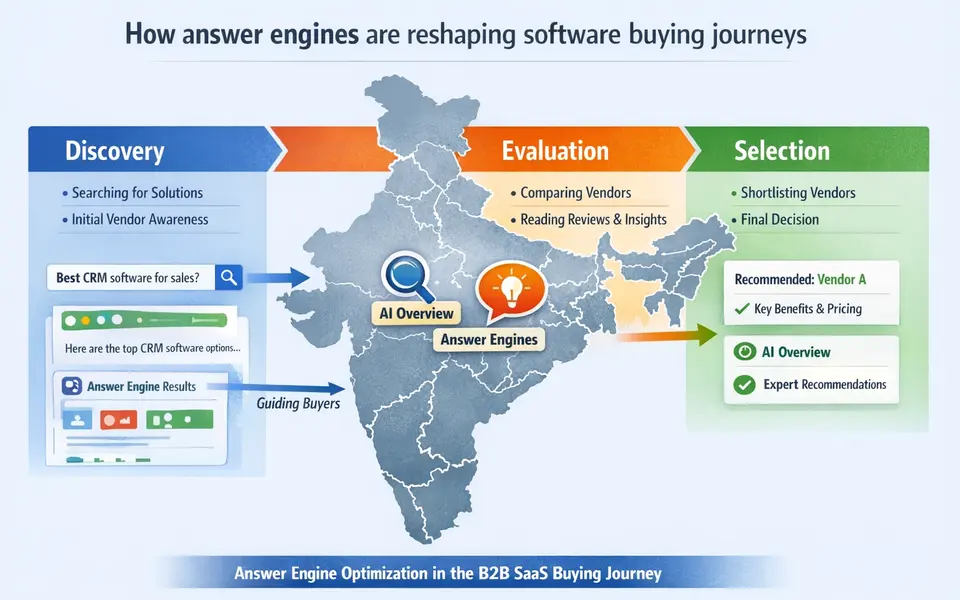
Explains how answer-engine visibility can offset paid acquisition in software buying journeys.
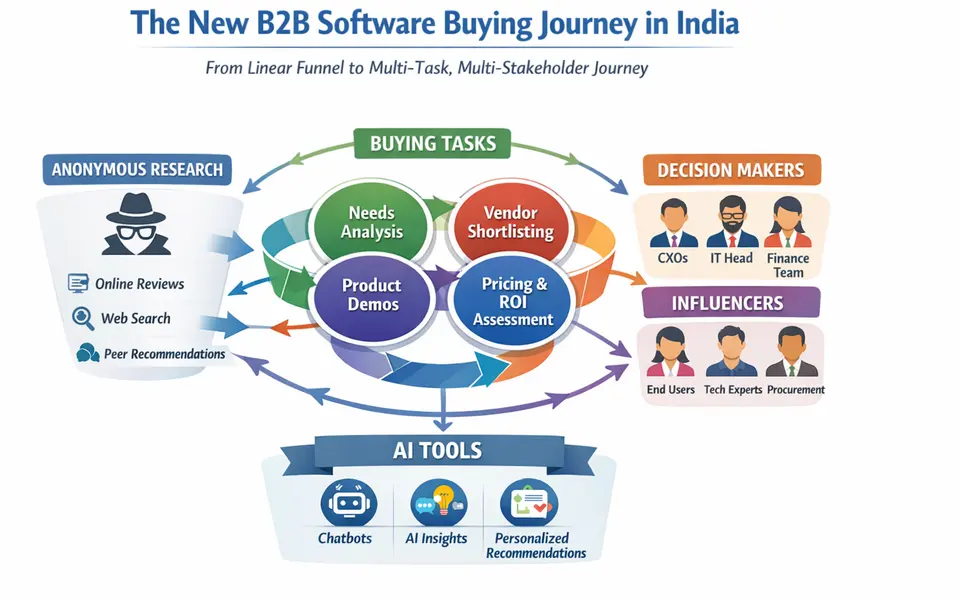
Shows how research-style reports can help a software brand shape category language and evaluation criteria.
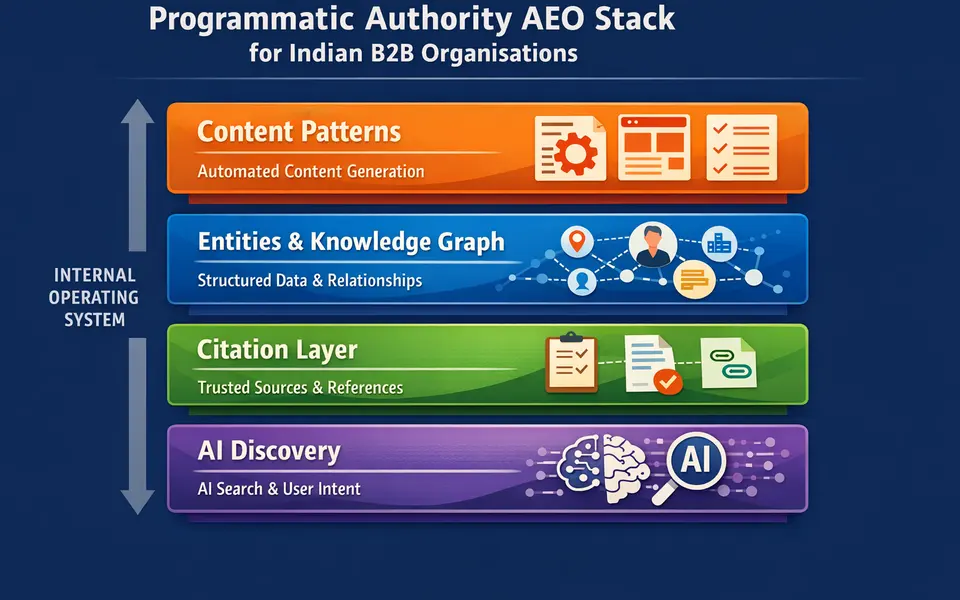
Compares the cost of building owned content assets with the compounding cost of buying traffic every month.
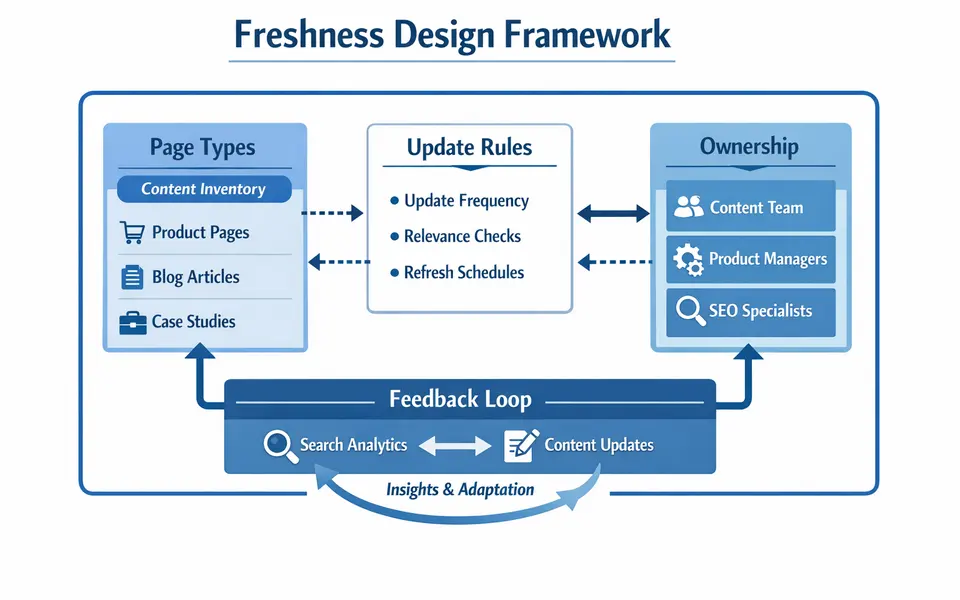
Explains how to update pages without breaking authority and how freshness interacts with trust.
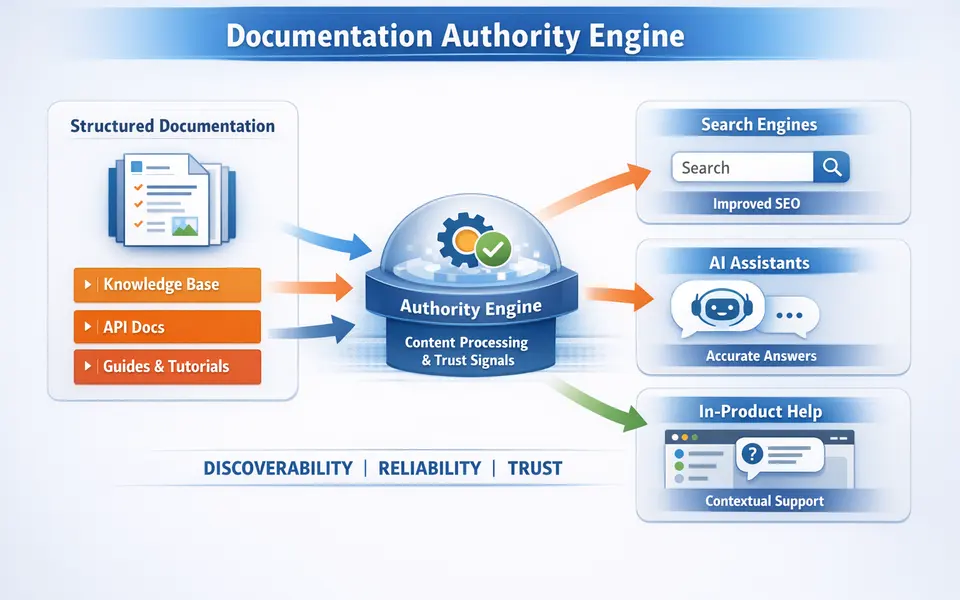
Explains how help centers and docs can become one of the strongest machine-readable trust layers for SaaS brands.